
How is Google Translate able to understand text and convert it from one language to another? How do you make a computer understand that in the context of IT Apple is a company and not a fruit? Or how is a Smart-Keypad able to predict the most likely next few words that you are going to type? These are examples of tasks that deal with text processing and come under the umbrella of Natural Language Processing (NLP).
We have an intuitive capability to deal with text, but with millions and millions of documents being generated every day, computers need this intuitive understanding of text data as well. They need to be able to understand the nuances implicitly encoded into our languages. Humans cannot be sitting behind Smart Reply or Google Translate. Here is where Word Embeddings come into play.
What are Word Embeddings?
Word embeddings transform human language meaningfully into a numerical form. This allows computers to explore the wealth of knowledge embedded in our languages.
The main idea here is that every word can be converted to a set of numbers – N-dimensional vector. Although every word gets assigned a unique vector/embedding, similar words end up having values closer to each other. For example, the vectors for the words ‘Woman’ and ‘Girl’ will have a higher similarity than the vectors for ‘Girl’ and ‘Cat’. Usually these N-dimensional vectors are of length 300 (i.e. N equals 300). We will understand this better in a bit.
For these representations to be really useful, the goal is to capture meanings, semantic relationships, similarities between words, and the context of different words as they are used naturally by humans.
1. Simple Frequency based Embeddings
One-Hot Encoding
Let’s start by looking at the simplest way of converting text into a vector.
We could have a vector of the size of our vocabulary where each element in the vector corresponds to a word from the vocabulary. The encoding of a given word would then simply be the vector in which the corresponding element is set to 1, and all other elements are 0. Suppose our vocabulary has only five words: King, Queen, Man, Woman, and Child. We could encode the word ‘Queen’ as:

This simple technique of creating numerical representations is called One-Hot Encoding. Can you tell the problem with this approach? As you have probably figured out, this solution is neither scalable and nor smart. If we have a vocabulary of ten million words, it would mean that we would need vectors of size 10M, where each word would be represented by a single 1 and all other 9,999,999 elements would be set to 0. Besides the sparseness and huge memory requirement issues, this technique is also not able to capture any semantic relationships or context information. We cannot make any meaningful comparison between word vectors other than plain equality testing.
Tf-Idf is another popular technique for computing frequency based embeddings.
2. Prediction based Embeddings
Word2Vec
As we have just seen, deterministic frequency based methods to determine word vectors are limited in their capabilities. Natural Language Processing community had to live with such limitations until Mikolov et al. at Google came up with a brilliant solution called Word2Vec. Their proposed method has become the state of the art when it comes to word similarities and word analogies. Word2Vec astounded audiences by achieving feats like vector algebra on words:
King – Man + Woman = Queen
Some more interesting results achieved using Word2Vec:

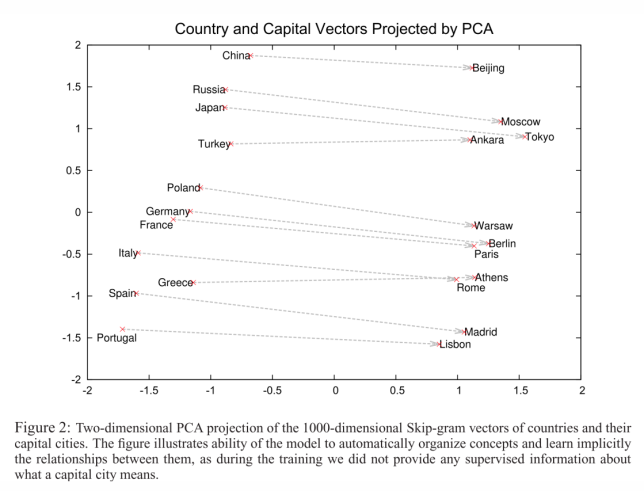

So let us try to understand this “magical” Word2Vec.
What if instead of a 1:1 mapping between vector elements and words we could have a smarter mapping? Can you think of some mapping technique that could allow us to use small vectors for representing very large vocabularies?
Continuing with the example used for One-Hot Encoding, we could try dimensions labelled ‘femininity’, ‘masculinity’, ‘age’ and ‘royalty’, with decimal values between 0 and 1.
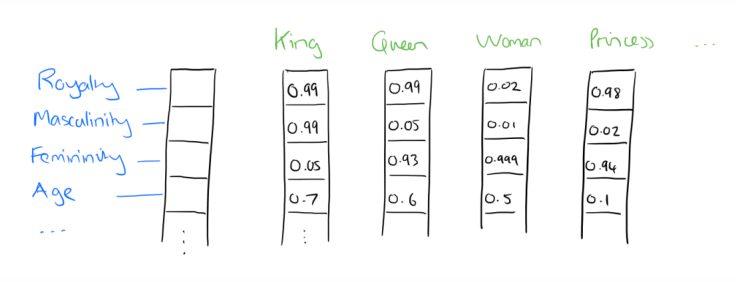
So what we have done is to essentially capture the meanings of the words in an abstract way. And as you can see, similar words have ended up with similar vectors – there’s a smaller distance between the vectors for ‘Queen’ and ‘Woman’, than the distance from ‘King’ to ‘Woman’. (Distance can be simply defined as the Euclidean distance.) Now we do not have large sparse vectors, so this technique is much more efficient in terms of memory as well. Moreover, the relationship between words has also been captured – the movement in the vector space from ‘King’ to ‘Queen’, is the same as the movement from ‘Man’ to ‘Woman’ or ‘Uncle’ to ‘Aunt’:

Creating N-dimensional vectors that are able to efficiently capture the meaning of words, such that the semantic relationships are maintained and similar words end up closer to each other, is not an easy problem. In our example above, we approached the problem by using some abstract dimensions like ‘Masculinity’ and ‘Royalty’. It is not possible to manually derive dimensions in a similar way when dealing with large vocabularies and hundreds of dimensions. And it is also not an easy task to design an algorithm that can achieve the same level of intuitions as humans.
2.1 Learning word vectors
“You shall know a word by the company it keeps” – Firth, J.R. (1957)
As we know well by now, one of the goals when training embeddings is to capture the relationships between words. The meaning of a word can be captured, to some extent, by its use with other words. For example, ‘food’ and ‘hungry’ are more likely to be used in the same context than the words ‘hungry’ and ‘software’.
The idea is that given any two words if these two words have a similar meaning, they are likely to have similar context words. And this is used as the basis of the training algorithms for word embeddings.
Word2Vec is a neural network based algorithm composed of two models –CBOW(Continuous bag of words) and Skip-gram. Basically, models are constructed to predict the context words from a centre word and the centre word from a set of context words. Lets look into both of these techniques separately and gain an intuitive understanding of their architecture.
CBOW (Continuous Bag of words)
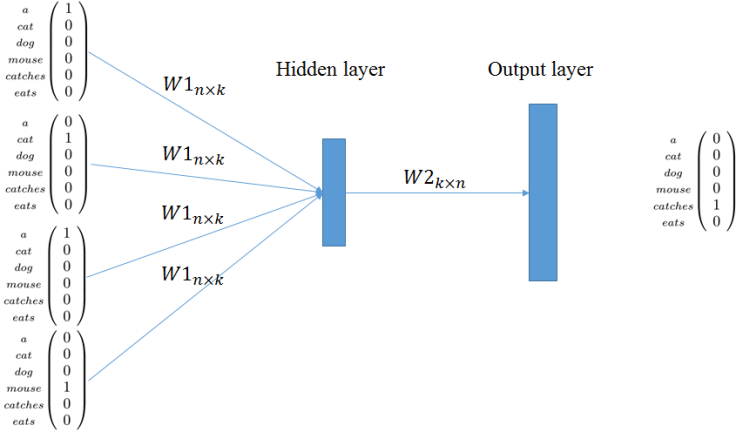
CBOW attempts to predict the probability of the center word from a given context i.e. group of words. Suppose there is a sliding window over our input text, with one word that comes before the center word and one that comes after it, like in the following image:

The context words become the inputs for the Neural Network, and the center word is predicted at the output layer. Each word is represented using one-hot encoding. This means that for a vocabulary of size V, we will have input and output vectors of dimension V. The objective of the training is to maximize the conditional probability of observing the actual output word from the input context words, with regard to the weights. Error between the output word and the actual target word is used to re-adjust the weights. In the example below, the neural network attempts to predict ‘catches’ given words like ‘a’ , ‘cat’ and ‘mouse’.
Skip-Gram model
The skip-gram model is the opposite of the CBOW model. It tries to predict the context words from a center word.

Just try to imagine flipping the architecture of CBOW. In this case the neural network is optimized to produce a vector with high values for the predicted context words. If our words are represented as one-hot encoded vectors of dimension V, and we are trying to predict N context words, our skip-gram architecture would look like as follows:

In this model, the training objective is to minimize the summed prediction error across all context words in the output layer.
Via Word2Vec work, Mikolov et al. also showed that it is possible to reduce the computational complexity of learning word vectors. This makes it practical to learn high dimensional word vectors on huge amounts of data. Although they used Google News corpus for training word vectors, they did not use the whole data set. The training corpus consisted of 6B tokens, while they restricted their vocabulary to the most frequent 1M words.
We have talked about Word2Vec, but various algorithms have been developed recently to create meaningful models that can learn word embeddings from large bodies of text. The most popular algorithms are:
End Notes
Did you enjoy learning about word embeddings? Hope that by now you have a good grasp of the topic. Gensim is a library that can be used to easily work with embeddings in Python. I will go through a practical example in a follow-up post.
Thanks for reading!
If you want to be notified when I write something new, you can sign up to the low volume mailing list by following this blog.
References and Further Readings
Efficient Estimation of Word Representations in Vector Space – Paper by Mikolov et al.
The amazing power of word vectors
Tensorflow Tutorial on Embeddings

I found this article well written and informative! Thanks Samia!
LikeLike
We found your pronounce and is useful for all.Thanks
LikeLike
I found some useful information in your blog, it was awesome to read, thanks for sharing this great content to my vision, keep sharing.
For more related to Skip-Gram Model Visit: https://insideaiml.com/article-details/The-Skip-gram-Model-139
LikeLike